import torchtext.datasets
train_iter, test_iter = torchtext.datasets.IMDB(
root='/home/jovyan/public/datasets/IMDB/',
split=('train', 'test')
)Learning From Text Using LSTM
1 Get the dataset
import pandas as pd
def load_dataframe(iterator):
data = list(iter(iterator))
df = pd.DataFrame(data, columns=['sentiment', 'review'])
df['sentiment'] = df['sentiment'] - 1
return dfimport torchtext.data
from torchtext.vocab import build_vocab_from_iterator
from tqdm.notebook import tqdm
tokenizer = torchtext.data.get_tokenizer('basic_english')
def iterate_tokens(df):
for review in tqdm(df['review']):
yield tokenizer(review)
df = load_dataframe(train_iter)
vocab = build_vocab_from_iterator(
iterate_tokens(df),
min_freq=5,
specials=['<unk>', '<s>', '<eos>'])
vocab.set_default_index(0)
len(vocab)301242 Dataloaders
import torch
from torch.utils.data import (
TensorDataset,
DataLoader,
random_split,
)
from torch.nn.utils.rnn import pad_sequence
sequences = [
torch.tensor(vocab.lookup_indices(tokenizer(review), ), dtype=torch.int64)\
for review in df['review']
]
padded_sequences = pad_sequence(sequences, batch_first=True)[:, :250]
sentiments = torch.tensor(df['sentiment'], dtype=torch.int64)
dataset = TensorDataset(padded_sequences, sentiments)
(train_dataset, val_dataset) = random_split(dataset, (0.7, 0.3))
batch_size = 32
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
val_dataloader = DataLoader(val_dataset, shuffle=True, batch_size=batch_size)3 End-to-end sequence classifier
import torch
import torch.nn as nn
from lightning.pytorch import LightningModule
from torchmetrics import Accuracy
class MySequenceClassifier(LightningModule):
def __init__(self, vocab_size, dim_emb, dim_state):
super().__init__()
self.embedding = nn.Embedding(vocab_size, dim_emb)
self.lstm = nn.LSTM(input_size=dim_emb,
hidden_size=dim_state,
num_layers=1,
batch_first=True)
self.output = nn.Linear(dim_state, 2)
# will be monitoring accuracy
self.accuracy = Accuracy(task='multiclass', num_classes=2)import torch.optim
#
# the rest
#
class MySequenceClassifier(MySequenceClassifier):
def forward(self, seq_batch):
emb = self.embedding(seq_batch)
_, (state, _) = self.lstm(emb)
# state: (num_layers, batch, dim_state)
output = self.output(state[-1])
return output
def loss(self, outputs, targets):
return nn.functional.cross_entropy(outputs, targets)
def training_step(self, batch, batch_index):
inputs, targets = batch
outputs = self.forward(inputs)
loss = self.loss(outputs, targets)
self.accuracy(outputs, targets)
self.log('acc', self.accuracy, prog_bar=True)
self.log('loss', loss)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters())
def validation_step(self, batch, batch_index):
inputs, targets = batch
outputs = self.forward(inputs)
self.accuracy(outputs, targets)
self.log('val_acc', self.accuracy, prog_bar=True)4 Training
from lightning.pytorch import Trainer
from lightning.pytorch.loggers import CSVLogger
logger = CSVLogger('./lightning_logs/', 'lstm')
trainer = Trainer(max_epochs=10, logger=logger)GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUsmodel = MySequenceClassifier(vocab_size=len(vocab),
dim_emb=32,
dim_state=64)
trainer.fit(model,
train_dataloaders=train_dataloader,
val_dataloaders=val_dataloader)Missing logger folder: ./lightning_logs/lstm
| Name | Type | Params
-------------------------------------------------
0 | embedding | Embedding | 963 K
1 | lstm | LSTM | 25.1 K
2 | output | Linear | 130
3 | accuracy | MulticlassAccuracy | 0
-------------------------------------------------
989 K Trainable params
0 Non-trainable params
989 K Total params
3.957 Total estimated model params size (MB)
/opt/conda/lib/python3.10/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:492: Your `val_dataloader`'s sampler has shuffling enabled, it is strongly recommended that you turn shuffling off for val/test dataloaders.
/opt/conda/lib/python3.10/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:441: The 'val_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=31` in the `DataLoader` to improve performance.
/opt/conda/lib/python3.10/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:441: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=31` in the `DataLoader` to improve performance.
`Trainer.fit` stopped: `max_epochs=10` reached.metrics = pd.read_csv('./lightning_logs/lstm/version_0/metrics.csv')
val_acc = metrics['val_acc'].dropna().reset_index(drop=True).to_frame()
val_acc.index.name = 'epochs'
val_acc.columns = ['LSTM_acc']
val_acc| LSTM_acc | |
|---|---|
| epochs | |
| 0 | 0.50440 |
| 1 | 0.52992 |
| 2 | 0.54548 |
| 3 | 0.57316 |
| 4 | 0.61564 |
| 5 | 0.71092 |
| 6 | 0.76944 |
| 7 | 0.81680 |
| 8 | 0.84912 |
| 9 | 0.86832 |
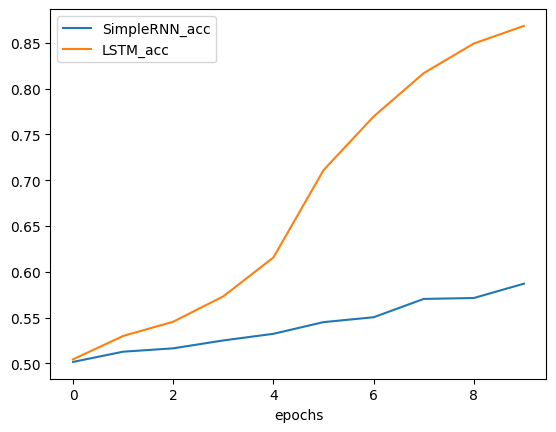
5 Compare with RNN
metrics_rnn = pd.read_csv('./lightning_logs/version_1/metrics.csv')
val_acc_rnn = metrics_rnn['val_acc'].dropna().reset_index(drop=True).to_frame()
val_acc_rnn.index.name = 'epochs'
val_acc_rnn.columns = ['SimpleRNN_acc']
acc = val_acc_rnn.merge(val_acc, left_index=True, right_index=True)
acc.plot.line();
acc| SimpleRNN_acc | LSTM_acc | |
|---|---|---|
| epochs | ||
| 0 | 0.50160 | 0.50440 |
| 1 | 0.51276 | 0.52992 |
| 2 | 0.51644 | 0.54548 |
| 3 | 0.52504 | 0.57316 |
| 4 | 0.53228 | 0.61564 |
| 5 | 0.54504 | 0.71092 |
| 6 | 0.55036 | 0.76944 |
| 7 | 0.57036 | 0.81680 |
| 8 | 0.57136 | 0.84912 |
| 9 | 0.58700 | 0.86832 |